This section describes some of the aspects of the system that I feel are interesting from an architectural standpoint, as well as some of the problems encountered in implementing the system:
Bitmasks are represented as a pair of 32-bit integers that together constitute an 8x8 bitmask. Triage masks are represented by their C and V bitmasks (the A mask is computed from these as A = ~(C|W) ). Compositing operations for bitmasks are implemented as simple bitwise logical operations.
There are several heavily used operations which, if implemented poorly, could require an iteration through all 64 bits of the mask. These operations are:
For counting bits, I use the approach described in the A-buffer paper (Carpenter '84). Intel processors do not have a bitcount instruction, so to count the bits in a 32-bit integer, I shift the bits out 8 at a time and use the shifted-out bits as an index into a precomputed 256-entry table which stores the number of bits that are set in each 8-bit character. This operation is performed 4 times to count the bits for the whole integer.
For setting rectangular regions in a bitmask, I use two precomputed 8x8 tables, called 'above' and 'below'. Entry (x,y) in the 'above' table has all bits above and to the right of position (x,y) set, and entry (x,y) in the 'below' table has all bits below and to the left of position (x,y) set. Thus, to compute a mask having only bits in the region (xl,yl)->(xu,yu) set, we AND together the masks above[xl][yl] and below[xu][yu].
Relevant Files: Bitmask and TriageMask operations are implemented by the Bitmask and TriageMask classes, both of which can be found in the files TriageMask.{h,cpp} .
I found that the most difficult task in implementing the system was getting the coverage masks right for the HCM camera. As mentioned earlier, to compute the triage mask for a given polygon, we first compute the triage masks for the polygon edges, then composite them together. To speed up this process, we precompute the edge triage masks before rendering begins. The perimeter of a square image region is divided into 512 evenly spaced sample positions. For each of the 512x512 pairs (in,out) of positions on the perimeter, we precompute the triage mask for the edge that enters the region at position 'in' and exits the region at position 'out', and store the mask in a 2-dimensional table indexed by in/out positions.
When we render, therefore, we need to find the intersection of each edge with the perimeter of the image region. The main considerations here are:
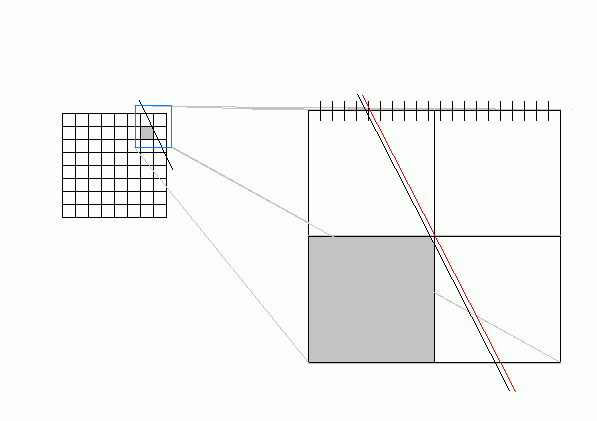
The edge "snapping" operation can potentially cause problems, especially if the polygon is small relative to the image region. The following figure illustrates the problem. The actual edge (in grey) intersects the highlighted region, but if we snap the edge to the perimeter, the snapped edge (in red) does not intersect the region, hence the hierarchical visibility algorithm will not descend into the shaded region. If the image region shown represents the entire image, the margin of error can be several pixels.
|
|
This problem causes unsightly holes to appear in polygonal meshes. The solution is to make the snapping process conservative, ie it always must snap edges towards the outside of the polygon. This may cause the hierarchical algorithm to descend into regions that the edge doesn't actually intersect, but the algorithm will figure this out when it tries to intersect the edge with the region.
Relevant Files: The main class for computing edge bitmasks/triage masks is the Edge class, found in the files Edge.{h,cpp}. Triage masks for polygonal faces are computed by the Tessellation and Triangle classes, found in Tessellation.{h,cpp} and Triangle.{h,cpp}, respectively.
A simple implementation of Greene's HCM algorithm would always tile polygons starting at the root node of the coverage pyramid. This node represents the entire image as an 8x8 grid of 64x64 pixel subregions (for a 512x512 image). Thus, to tile a small polygon located at the centre of the image, the edges of the polygon would have to be extended to the perimeter of the image and snapped to the nearest perimeter sample points. The "snapped polygon" formed by these snapped edges can be quite different than the actual polygon. The snapped poly contains the actual poly (due to the conservative nature of the snapping process), but it could be quite a bit larger than the actual poly, potentially causing the HCM algorithm to descend into several image regions intersected by the snapped poly but not by the actual poly. As mentioned above, the algorithm will eventually figure out that the actual poly doesn't intersect these regions, but only after several expensive polygon clipping operations.
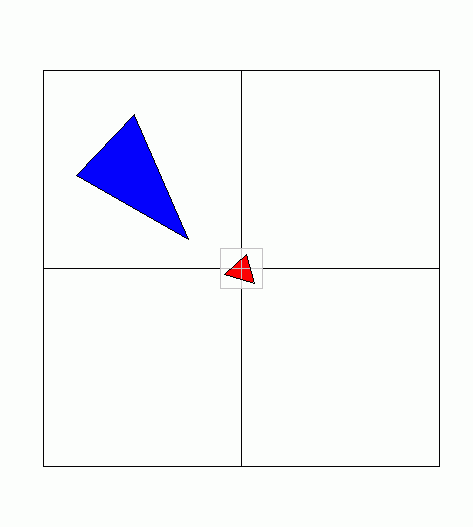
Greene suggests that one way to ameliorate this effect is to ensure that polygons are always tiled into image regions that are as small as possible, so the effect of the edge snapping is minimized. My implementation first finds the smallest coverage pyramid node that completely encloses the polygon. This is a good choice for a starting point if the poly lies completely within a node whose image region approximately matches the size of the poly, as is the case with the blue polygon in the figure below:
|
However, this is potentially a very bad choice for a small polygon that straddles the boundary between several very large pyramid nodes, as is the case with the red polygon in the figure. In this case, the smallest pyramid node that completely encloses the polygon is much larger than the polygon itself. In cases such as this, however, we can identify 4 much smaller nodes (shown in grey) that together completely enclose the polygon. We can then tile the polygon into each of these 4 nodes individually. This is the approach taken in my implementation.
Relevant Files: The coverage pyramid is maintained by the CoveragePyramid class, found in the files CoveragePyramid.{h,cpp}. This class performs the computation of the starting node(s) for tiling a polygon. The complete HCM algorithm is implemented by the CamHCM camera class, found in CamHCM.{h,cpp}.
Any practical scanline-based renderering algorithm must tessellate primitives into polygonal faces before rendering. RenderDude! uses the Tessellation class to represent a collection of polygonal faces originating from one or several primitives. Each SHAPE entity must provide a tessellate() method to tessellate itself. The Tessellation class stores the following data:
Relevant Files: The Tessellation class is implemented in the files Tessellation.{h,cpp}.
Before rendering, the HCM camera must organize all the faces in scene tessellation into an octree of BSP trees. RenderDude! uses the Octree class to construct the octree.
The Octree class is instantiated based on a particular Tessellation object. It constructs an axis-aligned octree spatial subdivision structure. Each node in the octree stores a list of indices that denote the faces of the tessellation that are contained in that node. Initially, the octree consists of a single node containing no faces.
In the Octree constructor, each face of the tessellation is added into the octree. When the number of faces in a particular node reaches a specified threshold (I use 50, as suggested by Greene), the node is split into 8 octants. All the faces in the node are split along the 3 median planes of the node and distributed to the new nodes representing the 8 octants. Any faces that are split during this operation are deleted and replaced in the tessellation by the 2 new sub-faces, each of which has the same face information (object id, plane equation) as the original face.
To facilitate front-to-back traversals, the Octree class provides a method for ordering all the leaf nodes in front-to-back order as seen from a particular viewpoint.
Relevant Files: The Octree class is implemented in the files Octree.{h,cpp}.
Once the octree has been constructed, a BSP tree must be constructed from the faces in each octree node. Thus, the BSPtree class is instantiated based on a Tessellation object and a list of faces which are to be organized into the BSP structure. Each octree node creates a BSPtree object based on the list of faces contained in that node.
In the BSPtree constructor, the first face in the list is used as a root, and all other faces are inserted starting at the root, splitting the faces as necessary. As with the Octree class, any split polygons are deleted from the Tessellation and replaced by the new subfaces.
The BSPtree class also provides a method to order its faces from front-to-back as seen from a particular viewpoint.
Relevant Files: The BSPtree class is implemented in the files BSPtree.{h,cpp}.
The "attributes" abstraction described in section 1 is implemented internally by the Attribute class and its various subclasses. The purpose of this class is to provide a unified framework for all operations involving properties of entities in the system. The relevant operations include:
RenderDude! entities can have attributes of various types:
Currently, the only attribute types that are texturable or animatable are Integer, Double, Vec2, and Vec3 attributes.
Entities in RenderDude! are all derived from the NamedEntity base class. This class provides an attribute list data item and a virtual method initializeAttributes() that subclasses override to add their attributes to the list. Since each attribute knows how to read and write itself, all file input/output is handled by the NamedEntity base class. Derived classes only need to make sure that they initialize their attribute list properly, and file I/O functionality comes for free.
As for textured and animated attributes, this is also handled at the base class level. When an attribute is read from a file, it either reads a value or the name of a texture or animation curve, which is then resolved to a Texture or AnimCurve pointer that is stored in the attribute itself. Again, this is transparent to the derived class.
When an entity needs to get the value of an attribute (say a shader needs the value of its color attribute), it first locates the attribute in the entity's attribute list, and calls an evaluation method on the attribute. This method will simply return the value of the attribute if it is untextured, otherwise it will evaluate the texture or animation curve that drives the attribute. Textured attributes are always recomputed when their value is requested, but animated attributes use an 'isDirty' flag to ensure that they are only evaluated once per frame. The 'isDirty' flag is set to TRUE whenever the current animation time is changed, and set to FALSE when the animation curve is evaluated for the attribute. Animated attributes are only re-evaluated when their 'isDirty' flag is TRUE.
Relevant Files: All attribute-related classes can be found in Attribute.{h,cpp}.
Memory usage is always a key consideration in a renderer. RenderDude!'s HCM camera is particularly memory sensitive, as it potentially performs many subdivision operations on an initially already very large polygonal database, causing the database to grow in size by a factor of as much as 20 (it appears that on average, the octree subdivision phase doubles the size of the database, then the BSP construction triples that increased size).
I needed a generic list class that could handle very large dynamic lists without having to perform a lot of heap reallocations and deallocations when the list size changes. I also wanted to keep the list in a contiguous array in memory to preserve locality of reference and to simplify indexing operations. James Stewart suggested that if I use a simple linear array in memory, and double the size of the array every time it outgrows the amount of memory allocated for it (a reallocation and copy is necessary here), then the amortized cost of an index into the array over the course of the program's execution is 3 times the cost of an index into a simple array. This is an acceptable cost to pay for a dynamic list, given that the cost of indexing into a traditional linked list would quickly become prohibitive as the list size grows into the hundreds of thousands or the millions (not uncommon in a renderer).
After the code was finished, I realized that my implementation of the HCM algorithm was not as fast as it should have been, I began profiling it to see where it was spending its time. As the system was developed in Developer Studio running on Windows NT, I had been linking with the Microsoft standard C libraries.
To my amazement, I discovered that the renderer was spending 20% of its time in one function, called __dtol . Tracing through the assembly code generated by the compiler, I discovered that this routine is invoked whenever a C cast is used to convert a floating-point value to an integer.
Scanning through the architecture documentation for Intel processors, I noticed that the processors support an instruction FISTP that performs this conversion. I replaced every instance of the type
int_var = (int)double_varwith a call to a new assembly subroutine
int_var = fastDblToInt(double_var)where fastDblToInt is implemented as
int fastDblToInt( double x )
{
int result;
_asm {
fpush x
fistp result
}
}
This code pushes the value onto the floating point stack, then invokes the FISTP operation to convert the value to an integer and pop the result off the stack, then returns the integer value.
The result of this change was that the __dtol routine disappeared from the profile results, replaced by the fastDblToInt routine, which now took up only around 1% of the total execution time. I was amazed (but pleased) that such a small change could speed up my renderer by 20% overall.
Actually just one other story, I accidentally tried to "optimize" my generic list class by replacing a loop that copied one list into another with a call to the system memcpy function. I had forgotten that the tessellation/octree/BSP tree construction performs a lot of such copies as new faces are added to the tessellation. The end result was that the overall running time of the renderer increased by a factor of 50!!!! Oops.