Beverly Harrison, Dept. of Industrial Engineering, University of Toronto, 4 Taddlecreek Road, Toronto, Ontario, CANADA, M5S 1A4, beverly@dgp.toronto.edu
Hiroshi Ishii, Computer Systems Research Institute, University of Toronto, 6 King's College Road, Toronto, Ontario, CANADA M5S 1A1, ishii.chi@xerox.com
Mark H. Chignell, Dept. of Industrial Engineering, University of Toronto, 4 Taddlecreek Road, Toronto, Ontario, CANADA, M5S 1A4, chignel@ie.utoronto.ca
In this paper we begin by presenting a framework for understanding interpersonal space in terms of interpersonal distance, angles of orientation, and gaze. We then describe an experiment that studied the influence of distorted space on distributed collaboration. Subject responses showed that positioning of monitors and the perceived orientation of the work partners had no significant effect on the amount of collaboration that was experienced. However, a face-to-face condition was experienced as being significantly more collaborative than video-mediated conditions. We also found a preference for a seating arrangement where the partners faced each other instead of sitting at an angle in a highly collaborative task.
KEYWORDS: Interpersonal distance, interpersonal space, shared workspace, media space, video conferencing, gaze awareness.
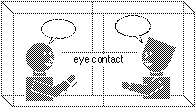
It has long been an unquestioned goal of telecommunication service to create a sense of "being there" by imitating the face-to-face communication (Figure 1). Currently, a great deal of effort is being spent in trying to approximate reality as closely as possible in media spaces. However, this goal needs to be reexamined since it is never possible to completely imitate reality [Hollan and Stornetta 1992]. Thus we believe it is not always necessary to remove all the discontinuities in the media space to achieve ultimate seamlessness or physical proximity, if the technology can reasonably support group of people to solve their problems.
A goal of our research is to understand the impact of these space distortions and discontinuities on technology-mediated collaboration, and to establish a practical theory of space interconnection for distributed collaboration. We believe psychological issues related to interpersonal communication influence the effectiveness of media space designs. These issues may be particularly important for systems which integrate shared workspaces with interpersonal spaces [Buxton 1992].
Figure 1. Undistorted interpersonal
space typical of face-to-face meeting
Current design and usage of media space systems has mainly focused on the creation of interpersonal space that maintains a sense of "telepresence" or "copresence" through the visibility of gestures and facial expressions of distributed group members. Important uses of media spaces include videophone calls, video conferencing, informal communication, and keeping social awareness [e.g., Mantei et al. 1991; Gaver et al. 1992a; Harrison et al. 1992a and 1992b; Bly et al. 1993; Fish et al. 1990 and 1993]. Current media spaces, however, do not yet succeed in providing natural and isotropic interpersonal space in which people can use various everyday nonverbal cues. Discontinuity between interconnected remote spaces results in distortion of extended space. Asymmetries arise because a variety of parameters are experienced differently (e.g. interpersonal distance) by the communicating parties. Parameters that are frequently asymmetric in video mediated interaction include; how close-up or far away someone appears, the angle they appear at, and the size they are displayed at. Figure 1 shows an isotropic interpersonal space in face-to-face meeting, and Figure 2 illustrates the distortion and asymmetry in media spaces. In Figure 2, person A's perceived interpersonal distance d1 is no longer equal or symmetrical to the interpersonal distance d2 perceived by person B.
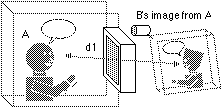
a) interpersonal space perceived by user A.
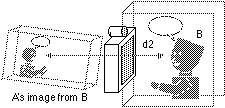
b) interpersonal space perceived by user B.
Figure 2. Distortion and asymmetry in media space
Another limitation of current media spaces is the ad hoc configuration of shared workspaces, typically consisting of groupware running in a computer screen next to a TV screen that shows the remote person's image. In these electronic shared workspaces, small mouse pointers are completely disembodied, and the discontinuity between the remote person's image and the shared workspace is amplified.
To understand the influence of distorted space on distributed collaboration, we first present a framework for understanding interpersonal space in terms of interpersonal distance, angles of orientation, and gaze. This framework is based on a literature review from social psychology and anthropology.
We then report an experiment which investigated the influence of spatial arrangement of interpersonal space and shared workspace on distributed and face-to-face dyadic collaboration. The experiment evaluated different video-mediated system configurations; across the table, at a right angle, and continuous/discontinuous hand images (relative to the image of the partner) in the shared workspace. Different video mediated orientations were obtained by changing the spatial arrangement of the monitors that showed the partner's image and the shared workspace. The video-mediated configurations were compared to similarly arranged face-to-face tasks.
The cues we use to control our interpersonal space and our accessibility to others include verbal, paraverbal, nonverbal, and environmentally oriented behaviors [McGrath, 1984]. These behaviors encompass, for instance, the kinds of information we self-disclose verbally, our tone of voice, smiling, looking, body orientation, posture, interpersonal distance, and our use of environmental "markers". Markers such as tables, desks, walls, and doors provide different barriers and controls which implicitly influence our availability and accessibility. Strong messages are conveyed through the use of markers and the behaviors associated with the control of personal space. These messages can encourage interaction, withdraw from an interaction, or prevent interactions from starting.
Each of the people in an interpersonal space may be sending messages of various kinds to one or more other people. The recipients of these messages may respond with like "messages" which maintain the current status quo. Alternatively, they can respond with "messages" that alter the level of the relationship making it more open or more closed, more or less personal. This is a dynamic and continuous exchange which they are often unaware of at a conscious level in spite of a rich set of messages being conveyed through visual orientation, facial expressions, sounds, silences, and the like [Argyle and Kendon 1967]. Distorting these cues can prevent interactions from ever starting or it can cause existing communication between people to break down. Thus failure to provide for these cues in the design of collaborative work technology may have severe implications for the functionality and usability of the resulting systems.
We place people within these distances based upon how well we know them, the context of our interaction or the task we are trying to accomplish, our relative status to each other, and our cultural background. If people are too close or too far (i.e., the perceived distance is inappropriate) we become uncomfortable and will adjust this distance by physically moving closer or further away. Cross cultural communication can often be characterized by observing two people apparently "chasing each other around a room", in effect unconsciously negotiating a conflict in perceived interpersonal space. In addition to feeling uncomfortable, inappropriate distances can cause us to assess others as "pushy", "withdrawn", "shy", "inattentive", or "unfriendly". These misperceptions affect human-human interaction and may even cause us to withdraw from an interaction altogether.
Sommers (1959) showed that differences in choice of seating location and in the direction faced depended largely upon the type of task. When two people are co-acting rather than interacting (e.g., sitting at the same table working on different things), they choose seats which are not face-to-face and which spatially separate themselves. When they are collaborating or having an informal conversation, they prefer to sit at right angles to each other. For competitive tasks the preference is to sit opposite one another. Close and side by side seating is the preference for intimate situations. In formal conversations, the leader typically faces as many members of the group as possible by sitting at the head of the table or standing at the front of the room (see next section). In all conditions, subjects preferred sitting in a location such as the rear of a room which gave them of view of anyone approaching.
Groups perform and interact in different ways as a result of collaborating or competing on different tasks [McGrath 1984]. For conversing, people tend to choose corner-to-corner or face-to-face orientations. For cooperating, they choose side-by-side orientations, while competing pairs tend to choose face-to-face positions.
The role and status of a person strongly influences which angle of orientation they will favor relative to other people in a group. Leaders, professors, and people of higher status tend to take the head of the table and face the group. Sommers (1959) concluded after much research into spatial arrangements and status influences, that a society compensates for blurred social distinctions by clear spatial ones.
Angle of orientation is not only influenced by the type of task and the status and relationship between individuals. The preferred angles are also clearly influenced by the visual angles afforded by facing certain directions. In dyadic interactions these angles may be influenced by objects which partially occlude one's view or by environmental constraints (e.g., the positioning of chairs and desks in someone's office).
Being able to see and read people's gaze is important. Gaze serves a number of critical functions in interaction including: communicating feedback about what is being discussed, communicating emotions, directing attention and indicating attentiveness, and regulating the flow of conversation [Argyle and Dean 1965; Argyle et al., 1973]. Gaze awareness [Ishii et al. 1993] tells people something about whether a person is looking at his/her collaborator or at the task. In some cases gaze direction indicates which part of the task is being looked at. This provides subtle cues which redirect attention to particular items of interest and thus facilitate coordination.
In face-to-face interactions we can observe not only a person's face but also gestures, nearby objects, and the immediate environment surrounding the person. This information supplements the conversation by providing cues about attention (or lack thereof), gestures, and work context. All of these subtle cues and constraints facilitate interaction, support coordination, and encourage or deter collaboration in face-to-face interactions.
ClearBoard realized very special (seamless) interconnection of two separated physical spaces using shared drawing surface as an interface [Ishii et al. 1993]. However, the integration of shared workspace and the partner's image into one continuous screen lead to less readability and less flexibility. Therefore, in this experiment, we decided to use separate screens, one for displaying the partner's image (person screen) and another for the shared workspace (workspace screen).
Shared workspace can provide a common frame of reference for the participants. It also creates an opportunity to coordinate the view of the partner with the image of the hand displayed in the workspace screen. However, the issues of how the person screen should be oriented relative to the workspace screen, and of how the partner's hands should be oriented in the workspace screen have yet to be addressed. Based on the discussion of the literature reviewed above, we can expect issues of orientation and hand positioning to have an impact on personal space variables such as gaze awareness, as well as on the overall sense of collaboration.
H1. Subjects will prefer working at an angle as it is more collaborative and less competitive than across the table.
H2. Subjects will experience more collaboration in a face-to-face condition than when the task is video mediated.
H3. Subjects will experience more collaboration when seated at an angle than when seated facing each other.
H4. The appearance of hands in the workspace screen will be seen as naturalistic and non-disruptive as long as the hands are presented in the workspace screen consistently with a virtual extension of the body in the person screen (i.e,. the hands appear to come from the same direction as where the body would be..
H5. Subjects will focus on the task (rather than their partner) when it has strong visual components (as in the experiment described below) and will use the auditory, rather than the visual, channel to communicate with their partners.
As illustrated in Figure 2, technological mediation introduces asymmetries in both the acoustic and visual dimensions of the setting, although the participants may inappropriately assume symmetry. To minimize the distortion and asymmetry in our experimental setting, we utilized the shared workspace to adjust the interconnection of physically separated two spaces. The shared workspace is expected to have the following three features for that purpose:
* WYSIWIS (What You See Is What I See),
* direct input to manipulate shared information, and
* hands images displayed in the workspace screen.
We decided to use the VideoDraw [Tang and Minneman 1991] configuration as one configuration of our experiment (labeled V2 below). We also developed two other video configurations that manipulated the apparent orientation of the partner relative to the subject, and the apparent positioning of the partners hands relative to their body.
Figure 3 illustrates the configuration of experimental system for the video mediated conditions. The shared workspace based on the VideoDraw technique allowed participants to see an image of the partner's hands as well as the objects and drawing on the workspace screen surface.
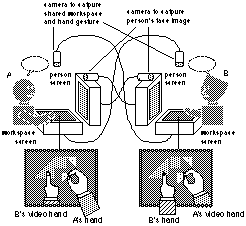
Figure 3 Configuration of experimental system
The video camera located above the workspace screen captures the drawing marks and any objects on the work surface. This image is sent to the monitor that displays the partner's work surface through a video network. The partner can draw or point directly over the transmitted video image. Video feedback between the two cameras and workspace screen pairs is prevented by the use of a polarizing filter placed over each camera lens and by the nearly orthogonal polarizing filter that covers the surface of each workspace screen.
Subjects worked at separate workstations about 15 feet apart, and were visually separated by a screen. However, they could hear each other by talking in a normal voice, with no amplification or electronic transmission of the sound being used.
The person screen displayed a view of the partner's head and upper body, allowing the partners to look at each other. The workspace screen was placed on its back facing up so that it acted like a desktop with a built in video image on its surface. For each subject, there was an overhead camera to capture the workspace view, and a camera over the monitor to capture a view of the subject's head.
The transparent plastic sheet with the template of the current tangram task was placed on top of subject A's workspace monitor. The resulting view was then captured by the overhead camera and displayed in video on subject B's workspace. Thus only one plastic sheet was used for each template, with Subject A viewing the sheet directly and subject B seeing a video image of the outline (template) on the plastic sheet. Subject B overlaid her tangram pieces on her workspace (using the video image of the template on subject A's workspace as a guide) and the overhead camera captured the image of the tangram pieces which were then displayed on subject A's workspace. The position of the cameras was carefully calibrated so that when subject B placed her puzzle pieces inside the tangram template as shown on her monitor, the corresponding video image of the pieces appeared to fall within the corresponding region of the template as displayed on A's workspace monitor. No sophisticated software transformation of the video signals were used between the two participants. Instead we relied on careful positioning and calibration of monitors, cameras, and lighting to achieve the desired effect of the collaborative workspace.
In addition to the video equipment used to create the video mediated collaborative environments, we also made extensive video records of the experiment. These included a video tape of one of the subjects in the video mediated condition, a video tape of both subjects working in the face to face condition, and a videotape of the views captured on all four monitors in the video mediated condition. The views from the four monitors were then merged into a picture-in-picture device where the views of each subject were shown in the top left and top right positions, while the corresponding workspace views were shown in the lower right and lower left positions. Figure 4 shows a frame from picture-in-picture view of the experimental setup in the video mediated condition.

Figure 4 A picture-in-picture snapshot of
the video-mediated experimental task
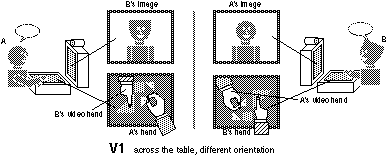
V1: Subject A was shown as a video image on a monitor opposite (facing) subject B. Subject A's hands were then shown as coming from the direction of the person screen, as if they were attached to A's body (virtual extension of the body).
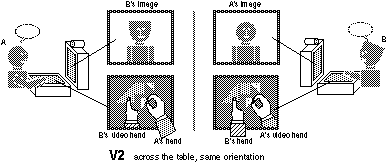
V2: Subject A was again shown as facing subject B, but this time A's hands were shown parallel to the hands of subject B (discontinuous from the image of A on the person screen). This situation mimics VideoDraw in that both parties now see the same orientation of the task image but A's hands are no longer a virtual extension of A's body.
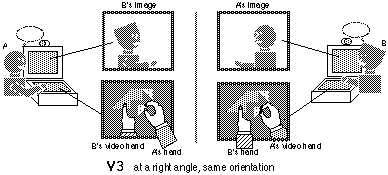
V3: The monitor was placed at right angles so that subject A appeared beside (at 90 degrees to) subject B. The hands were then arranged as in the V2 condition.
The different locations used across the three video mediated conditions were created by altering the position of the monitor (and attached camera) that showed the view of the partner. In condition V1, the person screen showing the image of the partner was placed opposite the subject. The effect of having the partner's hands come from the opposite direction (i.e., consistent with their image) was created by rotating their workspace screens 180 degrees relative to the other monitor. In condition V2, the set up was identical except that the workspace screens were rotated back so that they were now viewing the same orientation of the tangram. As a result the partner's hands now seemed to be coming from the same direction as the subject's hands.
In condition V3, the same workspace screen position was used, so that the hands again seemed to be coming from the same direction. However, the position of the person screen displaying the partner (and the attached camera transmitting the subject's image to the partner) was changed so that it was to the side, rather than in front of the subject (simulating the face to face condition of F2, as shown in Figure 6). The resulting effect, for both subjects, was that their partner's image was to their side, and if they turned around to look at their partner, the partner would see the image of the subject turn towards her just as in the corresponding face to face situation, although naturally without the complete fidelity and "presence" of actually being seated at the same table.
______________________________________________________________________________
______________________________________________________________________________
______________________________________________________________________________
Figure 5 Experimental settings of video-mediated conditions
Five pairs of subjects were randomly assigned to each of the three video conditions (30 subjects in total). In addition to participating in a video condition, each pair of subjects also participated in a face-to-face condition. The face-to-face conditions seating arrangement reflected the video arrangements as closely as possible as shown in Figure 6.
F1: For conditions V1 (face opposite, hands opposite) and V2 (face opposite, hands parallel), the corresponding face-to-face condition had the partners sitting opposite each other across a table.
F2: For condition V3, where the subjects were seated at right angles to each other, subjects sat at right angles around the corner of a table.
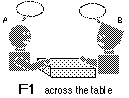
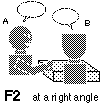
Figure 6 Experimental settings of face-to-face conditions
Each pair of subjects participated in one face-to-face and one video condition, with the ordering (face-to-face first, or video first) being counterbalanced across the subject pairs in the experiment. The sequencing of conditions was also counterbalanced across the experiment to prevent systematic differences due to time of day, experience of the experimenters in running the experiment, etc. Comparisons were made within subject for the face-to-face versus video condition and between subjects for the 3 video conditions relative to each other. Task performance (completion time) was compared within and between subjects. Subject pairs performed 2 Tangram tasks (described below) in each condition, requiring about 15 minutes of interaction per condition, or 30 minutes for the entire experiment.
The data collected during the experiment included:
* questionnaire responses (collected separately after each of the face-to-face and video conditions experienced by each group)
* the times taken to solve each of the tangram problems
* video tape data of verbal protocols and interactions for later detailed analysis.
Questions were rated on a seven point Likert scale, ranging from strongly disagree to strongly agree (see Appendix). One question showed a diagram of the "work space" and asked the subject to diagramatically show where they would have preferred their partner to be located (if they did not like the location which was provided).
Detailed video analysis will also be carried out using the Timelines computer-based video tool developed in our lab [Harrison 1991]. Gaze awareness will be determined by analyzing the subjects' head and eye movement from the video. In addition, task completion times, perceived frustration levels, and verbal protocols will be inferred from the video taped records. In this paper we will discuss the questionnaire data collected in the experiment. We plan to report on the videotape data at a later time.
To satisfy the above mentioned requirements, we decided to use simple puzzles (Tangrams) which had no particular orientation cues (no upside down or right-side-up) as shown in Figure 7. Subjects were asked to collaboratively solve Tangram problems. All Tangrams consisted of 7 pieces which were randomly divided into one group of 4 pieces and one group of 3 pieces. This balanced the work which would be required of each subject. The pieces had to be aligned to fill an outline of a solution shape. Pilot testing indicating that 3 of the 6 shapes were "difficult" and 3 were "easy"; difficult shapes required up to 10 minutes to solve, while easy shapes took 1 to 3 minutes. For instance, the middle tangram in Figure 7 was found to be "easy" by most subjects, whereas the more regular shape on the right (the arrow) was generally found to be "difficult". Subject were given 2 Tangram tasks per condition (15 minutes of interaction). Some subject groups that finished particularly fast were given one additional task to ensure equal interaction times. The tasks were randomly assigned, one from each level of difficulty. All subjects successfully completed the tasks before filling out questionnaires.
Figure 7 Examples of Tangram puzzles
In the face-to-face condition subjects were told to move only their own pieces. Pieces were labeled and colour coded to facilitate identification. In the video mediated conditions the pieces were set up in different locations but the images were projected to the partner's workspace screen.
The questionnaire contained 13 questions (Part I) which were repeated for both the face to face and video mediated conditions. After question 13 they were shown a diagram of locations around a table and asked to circle the position in which they would have preferred their partner to sit (either opposite or side by side). Another three questions (Part II) were added for the video conditions only. The questions used in Parts I and II of the questionnaire are shown in the Appendix.
Eight of the questions (numbers 1, 2, 3, 4, 5, 10, 11, and 12) were designed to address issues relating to the quality of collaboration between the two partners in each group. Four questions (6, 7, 8, and 9) addressed the issue of gaze awareness. Question 13 addressed the issue of preferred relative location. An identical seven point rating scale was used for each question, ranging from strongly disagree (coded as 1) to strongly agree (coded as 7).
Our first hypothesis was that the side by side working position would be preferred. We examined the preferred locations that subjects had indicated by circling a position on the diagram shown after Question 13 of the questionnaire. Each subject provided two preferred location judgments, one for the face to face condition that they experienced and one for the video mediated condition. We carried out a contingency table analysis on the resulting data to see if there was any relationship between this positional preference and the experimental factors (type of mediation, type of location).
Neither of the Chi-squared analyses (preference x location, preference x mediation) was significant. The data are summarized in the tables below. It can be seen that the opposite location was preferred overall. However, there was no tendency for this preference to vary according to the type of mediation, or the actual location of the partner. Table 1 shows the frequency table of location preference (opposite vs. at an angle) by actual location used in the video condition. The overall preference for the opposite position (33 out of 51) was significant (p<.05) when tested by the normal distribution approximation to the binomial (with correction for continuity). The preference was not due to more of the subjects experiencing the opposite condition (two conditions, V1 and V2, versus only one position at an angle, V3), because a majority of those who expressed a preference in the V3 condition (12 out of 17) also preferred the opposite condition.
Table 1 Location Preference by Video Condition
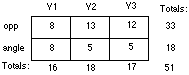
Table 2 shows the frequency table for location preference by mediation. It can be seen that the preference for the opposite position occurred for both the face to face and mediated conditions.
Table 2 Location Preference by Media
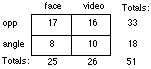
Thus the results contradicted our first hypothesis. Instead of preferring the side to side position identified in the previous literature as being "collaborative", subjects in our study preferred the supposedly competitive position, in spite of having carried out a highly collaborative task.
Our second hypothesis was that the face to face condition would be experienced as more collaborative than the video mediated conditions. We did a factor analysis of the questionnaire and found one factor (accounting for 37%) of the variance that we interpreted as "collaboration". We then compared the collaboration factor scores between the face to face and video conditions. Using a one tailed t-test (expecting to find greater collaboration in the face to face condition) we found that the scores on the collaborative factor were significantly higher (p<.05) for the face to face group. However, the collaboration scores did not differ significantly between the different video conditions (V1, V2, and V3), thus contradicting our third hypothesis that subjects will experience more collaboration when seated in a side by side position than when seated facing each other.
Our fourth hypothesis was addressed by three additional questions that were asked in the video condition. They are shown in the Appendix as Questionnaire: Part II. Figure 8 shows a plot of the mean ratings for each of these questions. In general, the participants agreed with the first two statements that they were comfortable with the positions of the hands (5.3 out of 7) and that they found it useful to see the partner's hand in the display (5.5 out of 7). For the third statement "I found it disruptive to see my partner's hand in the display", they tended to disagree (2.9 out of 7), although not strongly (In Figure 8, we have plotted this data point as an agreement of 5.1 out of 7, flipping the scale, to prevent the visual impression of a major difference otherwise caused by the implied scale reversal with the negatively stated question). Thus there was general satisfaction with the positioning of the hands in the video mediated conditions.
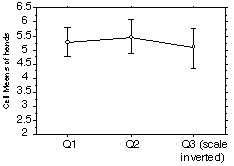
Figure 8 Mean responses to part II questions relating to
hand placement (with 95% confidence error bars)
Location (V1, V2, V3) did not have a significant effect on the subjects' statements about positioning of the hands in the video condition. Thus contradicting our fourth hypothesis. Subjects were not particularly sensitive to precise configuration of the hands in the display.
Our fifth hypothesis was that the subjects would focus on the task rather than their partners. This hypothesis was supported by our data. The subjects were aware that their partners were focusing on the puzzle (as shown by the high agreement with question 7, 5.8 out of 7), although this did not affect their ability to get the attention of their partners (as indicated by the low mean rating of 2.5 out of 7 obtained for question 8). Observation of the videotape collected in the experiment indicated that subjects used speech to discuss the task with their partners, but generally did not look at the image of their partner while performing the task.
Aside from the confirmatory analysis based on the hypotheses, we also carried out an exploratory analysis of the questionnaire results. Multivariate analysis of variance (MANOVA) with questions one to thirteen as the dependent variables, and location (V1, V2, V3) as the independent variables, was used. The only significant effect, as assessed by Wilk's Lambda, was for the mediation factor (F[2,5,20]=2.26, p<.05). We then carried out univariate mixed analyses of variance (with mediation as the within subjects factor and location as the between subjects factor) to determine the source of this effect. There was a significant difference only for question 13 (F[1,27]=10.27, p<.01).
Questions 13 referred to the statement "I would have preferred my partner to be in another location". Participants tended to disagree with that statement more in the face to face condition (2.5 out of 7) versus the video mediated condition (3.9 out of 7). Thus subjects tended to be less comfortable with the apparent location of the partner in the video conditions. Since we had hypothesized that location would be an important issue in the video conditions, we had expected that there would also be a significant effect of location, however there was no main effect of location nor was there an interaction of main effect and mediation for question 13 (F<1 in both cases). Figure 9 shows the data for question 13.
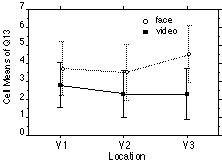
Figure 9 Mean scores on question 13 across the
different conditions for media and location (with 95% confidence error bars)
Figure 10 shows a plot of the mean scores for the 13 questions across the two mediation conditions. It can be seen that the confidence intervals for the questions generally overlap except for Question 13 (where the effect of mediation was significant, as reported above). The large dips in the figure (questions 8, 9, and 13) reflect disagreement to negative questions, rather than a significant difference in opinion. Thus the interesting distinction is between questions that the participants answered positively (either agreeing with a positive statement or disagreeing with a negative statement) and questions that received a neutral response (i.e., Questions 6 and 10).
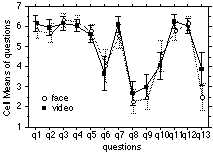
Figure 10 Mean scores for 13 questions across the different
media conditions (with 95% confidence error bars)
Questions 8 and 9 referred to statements about the participants having difficulty in getting each other's attention. The participants generally disagreed with these statements. In the video mediated conditions (V1, V2, V3) the participants tended to focus on the task and use voice, rather than visual signals, to attract the attention of their partner. The neutral rating for question 6 reflects the fact that the participants were generally unaware of where there partner was looking because their attention was focused on the puzzle. In addition, by seeing the partner's hands actively involved in manipulating the puzzle pieces almost continuously, they could reasonably assume that the partner was similarly focused on the puzzle.
Although the subjects enjoyed carrying out the task (as shown by the high ratings of between 5.8 and 6 out of 7 for questions 1, 2, and 11), they did not feel that the task was easier when done with a partner (as shown by the neutral mean rating of 4.3 for question 10).
The high mean levels of agreement to questions 3 (6.2 out of 7), 4 (6.2 out of 7), 5 (5.7 out of 7) and 12 (6.1 out of 7) generally indicated good subjectively experienced collaboration in terms of the cooperation between the partners ("I felt my partner listened to my advice", "I listened to advice from my partner", "I felt my partner understood what I wanted").
One of the features of the results shown in Figure 10 is that there was very little difference in the pattern of responding to the questions between the video and face to face conditions (as shown by the parallel and generally overlapping curves for the face-to-face and video data across the first 12 questions. With the exception of question 13, there are no statistically significant differences between the questions, suggesting that the subjective response to the face and video conditions are quite similar.
One explanation for our results may have been that participants were so focused on the task that they did not experience the type of gaze awareness and eye contact that would otherwise have been experienced in the face-to-face situation. Videotapes records from the experiment showed that participants rarely looked at each other in either the face-to-face or video mediated conditions. However our results did suggest that collaboration was generally experienced to be better in the face-to-face condition.
Overall, our results indicate that better collaboration is experienced in the face-to-face condition, but that there was no significant difference in the amount of collaboration experienced between the different video conditions (V1, V2, and V3). Thus people appeared to be less sensitive to changes in the configuration of the video mediated image and work spaces than we had expected.
The subjects in our experiment did not seem to have much concern about the positioning of the partner's hands in their workspace. They found the positioning of the partner's hands in the display useful, and they generally stated that they were comfortable with the positioning of the partner's hands in the display in all three of the video conditions. One of the reasons for this result may have been that the task did not have a strong orientation component, since the tangrams we used did not have a clear "up" or "down" orientation. Thus it did not matter if one partner was actually viewing the tangram from a different orientation than the other partner. We expect that the precise position of the hands may be more critical in tasks that have a strong orientation (e.g., collaborative writing where the text can be right way or wrong way up).
For the highly collaborative task that we used in this study, both video and face to face conditions were experienced positively by subjects. However, the face to face condition seemed to be superior both in terms of the greater experienced collaboration it produced and in terms of subjects being less likely to want a different seating arrangement than the one they experienced. Thus, although there appeared to be general satisfaction with the video mediated environment that was used, there are still important components of the face-to-face situation that are not being captured in our video mediated setups.
One of the subjects in the experiment commented that tilting the workspace monitor upwards a little (e.g., at a 20 or 30 degree angle) might have encouraged more viewing of the other person's image in the video mediated conditions since it would then have been possible for the subject to switch their gaze more easily between the partner's image and the workspace. We think that this is an interesting possibility for future research.
Overall, our findings indicate that completely imitating the nature of a face-to-face meeting may be an inappropriate design goal for media spaces. We need further research on the design of media spaces to find the most significant factors that determine the effectiveness of remote collaboration. These factors may differ from the obvious parameters of interpersonal space that have been studied in proxemics and related investigations of face-to-face communication.
Our experimental study found that the effectiveness of different video mediated layouts is not as sensitive to interpersonal space factors as might have been expected from a review of the literature on interpersonal space. Our study focused on the physical orientation of the two work partners in face to face and video mediated conditions. In terms of the questionnaire responses, we found no significant differences between the three different video mediated conditions that we used in terms of amount of collaboration, enjoyment or preference for alternative orientations.
The experiment reported here represents an initial attempt to better understand the influence of distortion and discontinuity in the media space. The subjective responses of participants in our experiment proved surprisingly resilient to both changes in mediation (video vs. face to face) and in the physical arrangement of the partners (opposite or side by side). While there are still detectable differences between the face-to-face and video mediated conditions, orientation of the partner's face and hands relative to the subject may not be a critical factor, at least in tasks which capture visual attention and where orientation of the workspace is not a major concern.
Further research is needed to determine the effects of different spatial arrangements for the shared workspace and interpersonal space in different tasks. While the present study showed that different spatial arrangements produced similar subjective responses, it should be noted that we were using a highly engaging and enjoyable task. Other tasks that require more interpersonal interaction, eye contact, and gaze awareness, will likely depend more strongly on spatial arrangement. In addition, people in less engaging tasks may be more likely to want a minimal level of social interaction, gaze awareness etc., as part of the overall task.
We hope that this experimental study will stimulate further studies on how theories of human-human interaction can inform or influence the design of collaborative systems. More research is needed to find out the critical dimensions along which video mediated collaboration differs from face-to-face collaboration. More understanding is also needed of how the characteristics of the task change the subjectively experienced nature of video mediated collaboration. For the task that we studied, orientation of the partner's head and hands was less important than we expected. However, orientation may still be a relevant factor in the design of other types of video mediated collaborative task.
Argyle, M., and Kendon. A. (1967). The experimental analysis of social performance. In L. Berkowitz (Ed.) Advances in Experimental Psychology. Vol. 3. New York: Academic Press.
Argyle, M., Ingham, R., Alkena, F., and McCallin, M. (1973). The different functions of gaze. Semiotica. 7. p. 10-32.
Bly, S.A., Harrison, S.R., and Irwin, S. (1993). Media Spaces: Video, Audio, and Computing. Communications of the ACM Vol. 36, No. 1 (January 1993), 28-47.
Buxton, W. (1992). Telepresence: Integrating Shared Task and Person Spaces. Proceedings of Graphics Interface '92, Morgan Kaufmann Publishing, Los Altos, 1992, pp. 123-129.
Fish, R.S., Kraut, R.E., and Chalfonte, B.L. (1990). The VideoWindow System in Informal Communications. Proceedings of CSCW '90, ACM, New York, 1990, pp. 1-11.
Fish, R.S., Kraut, R.E., Root, R.W., and Rice, R.E. (1993). Video as a Technology for Informal Communication. Communications of the ACM Vol. 36, No. 1 (January 1993), 48-61.
Gaver, W., Moran, T., MacLean, A., Lovstran, L., Dourish, P., Carter, K., Buxton, W. (1992a). Realizing a Video Environment: EuroPARC's RAVE System, Proceedings of CHI '92, ACM, New York, 1992, pp. 27-35.
Gaver, W. (1992b) The Affordance of Media Spaces for Collaboration. Proceedings of CSCW '92, ACM, New York, 1992, pp. 17-24.
Hall, E. T. (1963). The Silent Language
Hall, E. T. (1966). The Hidden Dimension. Garden City, NY: Doubleday Press.
Harrison, B. L., Chignell, M. H., and Baecker, R. M. (1992a). Do perceptions match reality? A comparison of objective and subjective measures in video mediated communication. Proceedings of the 25th Conference of the Human Factors Assoc. of Canada, p. 35-41.
Harrison, B. L., Chignell, M. H., and Baecker, R. M. (1992b). Out of site, still in mind? A case study in video mediated communication. Proceedings of the Human Factors Society 36th Annual Meeting, p. 242-247.
Hollan, J. and Stornetta, S. (1992). Beyond Being There. Proceedings of CHI '92, ACM, New York, 1992, pp. 119-125.
Ishii, H., Kobayashi, M. and Grudin, J. (1993). Integration of Interpersonal Space and Shared Workspace: ClearBoard Design and Experiments. ACM Transactions on Information Systems, Vol. 11, No. 4, October 1993, ACM, New York, pp. 349-375.
Mantei, M. M., Baecker, R. M., Sellen, A. J., Buxton, W. A. S., Milligan, T. (1991). Experiences in the Use of a Media Space. Proceedings of Human Factors in Computing (CHI '91), p. 203-209.
McGrath, J. E. (1984). Groups: Interaction and Performance. Englewoods Cliffs, NJ: Prentice-Hall, Inc.
Mehrabian, A. (1971). Verbal and nonverbal interactions of strangers in a waiting situation. Journal of Experimental Research in Personality. 1971. 5(2). p. 127-138.
Sommers, R. (1959). Studies in personal space. Sociometry. 1959, 22, p. 247-260.
Sommers, R. (1961). Leadership and Group Geography. Sociometry. Volume XXIV (1961). p. 99-110.
Sommers, R. (1969). Personal Space: The Behavioral Basis of Design. Englewoods Cliffs, NJ: Prentice-Hall, Inc.
Tang, J.C., and Minneman, S.L. (1991). VideoDraw: A Video Interface for Collaborative Drawing. ACM Transactions on Information Systems, Vol 9, No. 2, April 1991, New York, ACM Press, pp. 170-184.
Watson, O. M. (1970) Proxemic Behavior: A Cross-Cultural Study. The Hague: Mouton & Co. N. V., Publishers.
Please read each of the statements below and circle the number that best describes to what extent you agree or disagree with that statement.
1. I enjoyed performing the task.
1 2 3 4 5 6 7
strongly strongly
disagree agree
2. I believe that my partner enjoyed doing the task.
3. I felt my partner listened to my advice.
4. I listened to advice from my partner.
5. I felt my partner understood what I wanted.
6. I noticed whether my partner was looking at me or at the puzzle.
7. I felt that my partner was always looking at the puzzle.
8. I found it difficult to get my partner's attention.
9. I believe that my partner found it difficult to get my attention.
10. I believe that it was easier to do the task with another person than alone.
11. I believe that it was more fun to do the task with another person than alone.
12. I felt that my partner and I worked well together.
13. I would have preferred my partner to be in another location.
If you could have placed your partner, circle the position (letter) you would have preferred on the diagram below:
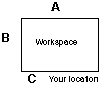
Please read each of the statements below and circle the number that best describes to what extent you agree or disagree with that statement.
1. I felt comfortable with the position of my hand relative to my partner's.
2. I found it useful to see my partner's hand in the display.
3. I found it disruptive to see my partner's hand in the display.